Streamlining App Development with on-platform Cloud tasks
Company
App development platform
My Role
Product Designer
Project duration
5 Months
My Contribution
User Interviews
User flows
Prototyping
High-fidelity designs
Testing and QA
Inefficient workflows
Users frequently encountered rate limits and service outages when their apps communicated with external services.
To avoid this, they were spending hours—sometimes even days or weeks—setting up systems using platforms like Temporal, Trigger.dev, or Google Cloud Tasks.
Why build this?
The current solution was time-consuming and contrary to the mission of helping developers build apps quickly and efficiently.
Recognizing these challenges, our team prioritized background jobs on the roadmap. My job was to ensure it met the needs of our users and aligned with our platform's goals.
Apps communicating with many external services
We established clear initial goals / assumptions:
Simplify complexity
Provide built-in background job capabilities to eliminate the need for external services.
Provide built-in background job capabilities to eliminate the need for external services.
Access to logs
Ensure that users have easy access to logs and historical data for monitoring and troubleshooting to quickly identify and resolve issues.
Ensure that users have easy access to logs and historical data for monitoring and troubleshooting to quickly identify and resolve issues.
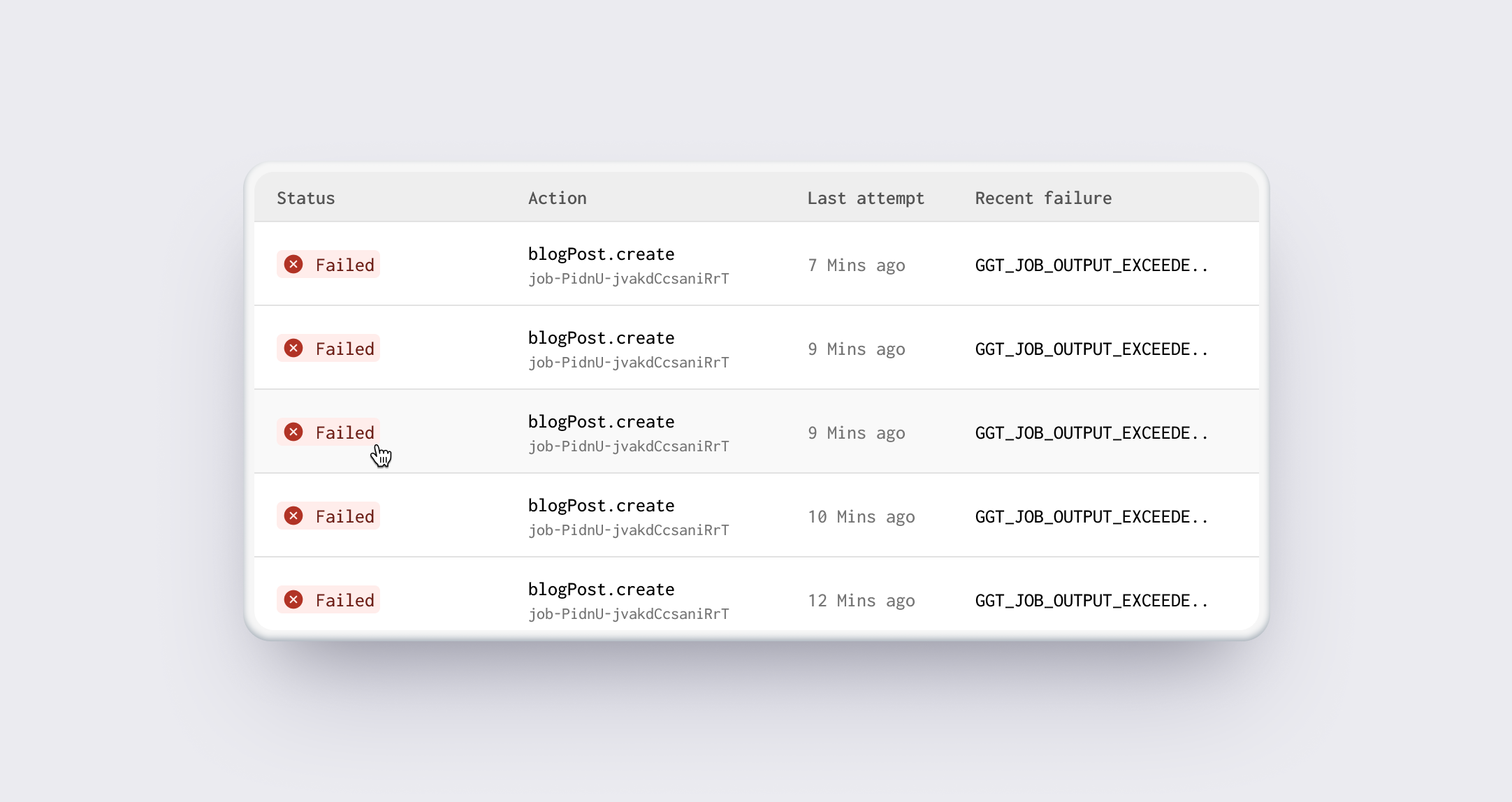
Failure differentiation
Highlight critical failures that require immediate attention, so users could prioritize their responses.
Highlight critical failures that require immediate attention, so users could prioritize their responses.

Insights from 7 power users
I created a set of questions covering configuration, monitoring, and testing to verify our assumptions + uncover hidden constraints or use cases. Here's what I learned:
User story #1: Task Prioritization
I need to set priorities for jobs so that user-facing, or critical tasks can jump the queue.
Ex: Applying a watermark to images could run over several hours, but user-facing tasks needed immediate execution.
I need to set priorities for jobs so that user-facing, or critical tasks can jump the queue.
Ex: Applying a watermark to images could run over several hours, but user-facing tasks needed immediate execution.
User story #2: Shop separation
I need to separate tasks based on the shop they came from, so that one shop does not hog the queue with an overflow or jobs.
Ex. If a large shop enqueues 1 million jobs, with no way to separate them, a mom and pop shop would have to wait a long time before their jobs ran.
I need to separate tasks based on the shop they came from, so that one shop does not hog the queue with an overflow or jobs.
Ex. If a large shop enqueues 1 million jobs, with no way to separate them, a mom and pop shop would have to wait a long time before their jobs ran.
User story #3: Cost Management:
I need to cancel jobs I know are going to fail, so that I don't pay for compute time which will never result in a successful run.
Ex. I enqueue 100,000 test jobs but realize there is a bug in my code.
I need to cancel jobs I know are going to fail, so that I don't pay for compute time which will never result in a successful run.
Ex. I enqueue 100,000 test jobs but realize there is a bug in my code.

Screenshot from a FigJam
Designing the solution
Leveraging the insights from user research, I collaborated closely with the engineering team to design background jobs.
User Interface Development:
Understand priorities, status levels and manage separate queues according to specific needs.
See job attempts, failures and when they happened.
Access logs and monitor job statuses in real-time. Cancel jobs proactively to manage resources and reduce costs.
Job status levels
Intuitive API Design:
I collaborated with engineering to ensure the coding experience was great too. We came up with a simple API call to kickoff a background action:
I collaborated with engineering to ensure the coding experience was great too. We came up with a simple API call to kickoff a background action:
Simplest invocation
api.enqueue(api.actionName, {firstName:"Background", lastName:"Jobs"...});
A more complicated invocation
api.enqueue(api.actionName, {
firstName:"Background",
lastName:"Jobs",
...
}, {
queue: {
name: "shop-name",
maxConcurrency: 4,
},
priority: "HIGH",
id: `shop-${shopId}`,
retries: 7,
startAt: "2024-09-02T12:00:00Z"
}
);
firstName:"Background",
lastName:"Jobs",
...
}, {
queue: {
name: "shop-name",
maxConcurrency: 4,
},
priority: "HIGH",
id: `shop-${shopId}`,
retries: 7,
startAt: "2024-09-02T12:00:00Z"
}
);
A customer describes their experience connecting NetSuite and Gadget with on-platform cloud tasks
"Something that I haven't been able to figure out (without Gadget) is simply get a clean error queue that doesn't have any unresolved errors.
In other systems, for certain error states you can't really clear them so you just have to remember which are a non issue vs those that are an issue.
Also retries sometimes you have to do manually.
In Gadget you can bulk retry all current failures (with one click) - and it' a very nice sanity check to have a clear error queue.
Also integrating with Sentry is great for error management. I'm sure you can do that in some (competitors) systems, but I think in others you can't.
Another thing I'm planning to do is use a single queue for all NetSuite api calls - what this allows you to do is set a max concurrency for your entire NetSuite integration to respect what NetSuite max concurrency you have on your account. This is also something other providers don't do a great job of."
- Gadget developer
In other systems, for certain error states you can't really clear them so you just have to remember which are a non issue vs those that are an issue.
Also retries sometimes you have to do manually.
In Gadget you can bulk retry all current failures (with one click) - and it' a very nice sanity check to have a clear error queue.
Also integrating with Sentry is great for error management. I'm sure you can do that in some (competitors) systems, but I think in others you can't.
Another thing I'm planning to do is use a single queue for all NetSuite api calls - what this allows you to do is set a max concurrency for your entire NetSuite integration to respect what NetSuite max concurrency you have on your account. This is also something other providers don't do a great job of."
- Gadget developer
The feedback was overwhelmingly positive
After launching the feature, real-world impact happened from day 1.
Easy to setup
With a one line code snippet to get a job queued it allowed users to quickly understand how the system worked, begin testing and getting a foot in the door of adopting the feature.
With a one line code snippet to get a job queued it allowed users to quickly understand how the system worked, begin testing and getting a foot in the door of adopting the feature.
Saved countless hours for experienced devs
All the functionality devs need is there. It's a familiar form-factor and integrates directly into the platform. Due to the code representation, our users could pick up the concepts easily. Experienced devs immediately hooked into the concept of queues, priorities, scheduling ahead of time and using custom identifiers
All the functionality devs need is there. It's a familiar form-factor and integrates directly into the platform. Due to the code representation, our users could pick up the concepts easily. Experienced devs immediately hooked into the concept of queues, priorities, scheduling ahead of time and using custom identifiers
Enabled junior devs to do something they never could do
Due to the simplicity, junior devs, vibe coders & indie-hackers are unblocked from running into rate limits and system outages with one line of code. They could adopt our preset defaults for retry count, backoff factor, interval between retries etc.
Due to the simplicity, junior devs, vibe coders & indie-hackers are unblocked from running into rate limits and system outages with one line of code. They could adopt our preset defaults for retry count, backoff factor, interval between retries etc.
2 Billion+
Jobs ran
20K+
Hours saved
400k+
USD saved
Mistakes were made in some areas
After launching the feature, real-world usage revealed some oversights in the design:
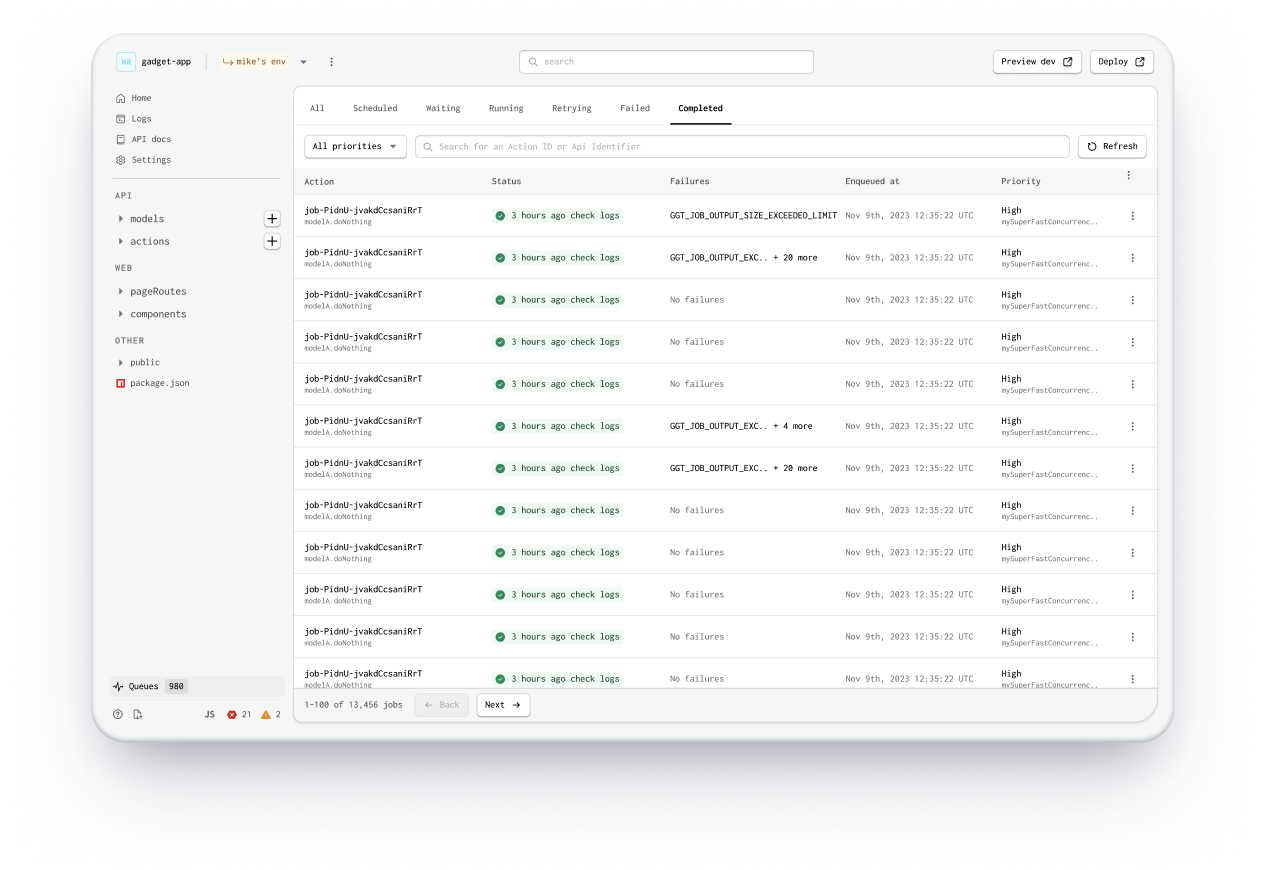
Cluttered Queue List
At the last minute we added platform webhooks, causing the queue list to be overwhelming as Shopify sends a large amount of these. Without a way to filter this out, users struggled to locate their own jobs.
At the last minute we added platform webhooks, causing the queue list to be overwhelming as Shopify sends a large amount of these. Without a way to filter this out, users struggled to locate their own jobs.
Navigation Issues
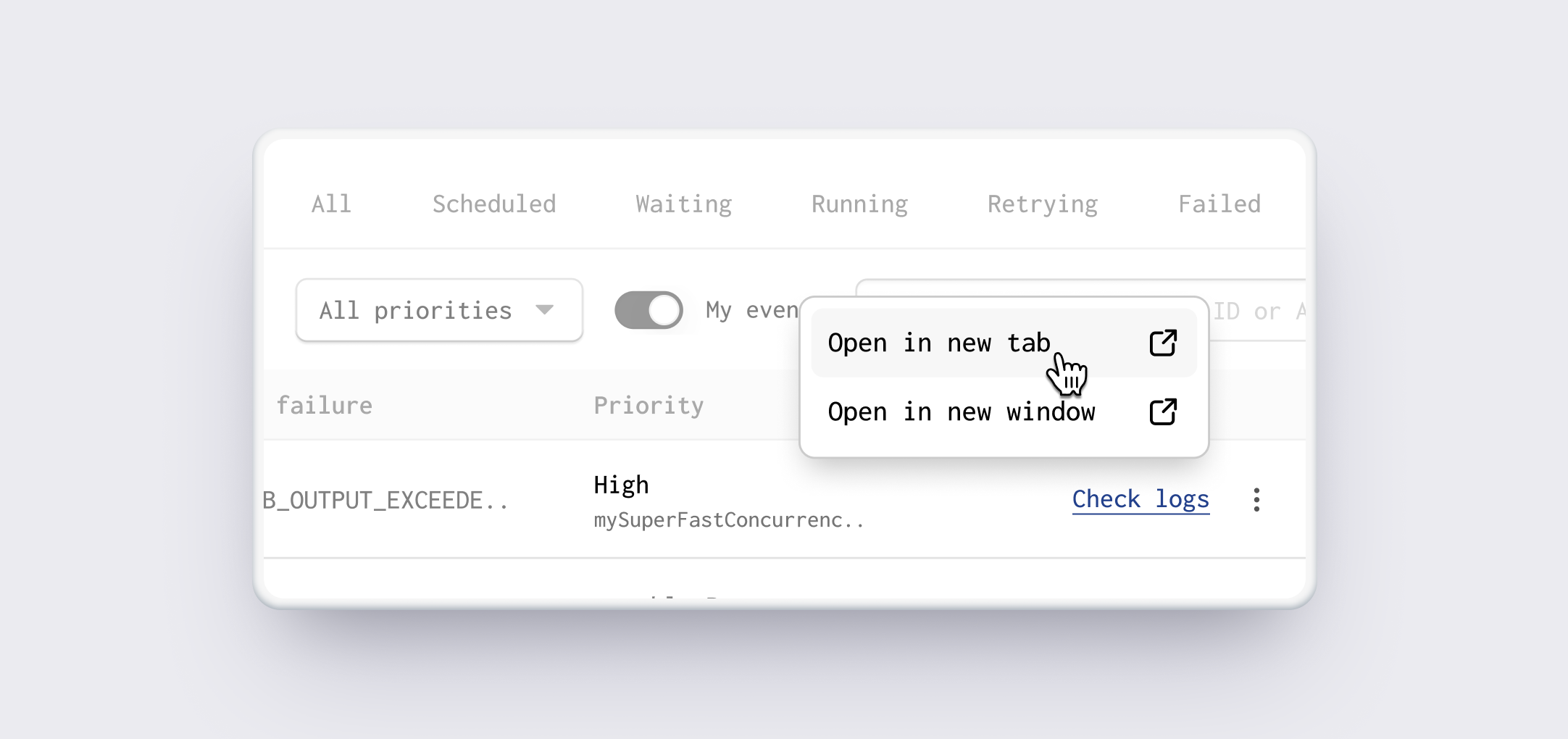
The initial implementation didn't wrap links in <a> tags, preventing users from opening multiple job logs in new windows.
The initial implementation didn't wrap links in <a> tags, preventing users from opening multiple job logs in new windows.
Performance Problems
Displaying the count of job attempts in the UI caused heavy database load, impacting system performance.
Displaying the count of job attempts in the UI caused heavy database load, impacting system performance.
What I learned from these mistakes
Ensure that proper <a> HTML tags are used - this allows you to hook into the browser default features like open in new window, open in new tab, copy link etc.
Last minute decisions are dangerous - push back against product teams and throughly consider the impact feature bloat can make on the user experience - be flexible and create other solutions.
Consider the performance impact of on-screen elements with data fetches, having a job attempt counter effectively caused the database reads to be 5-10x more.
Last minute decisions are dangerous - push back against product teams and throughly consider the impact feature bloat can make on the user experience - be flexible and create other solutions.
Consider the performance impact of on-screen elements with data fetches, having a job attempt counter effectively caused the database reads to be 5-10x more.
Iterating on the design
Recognizing these issues, I took the initiative to re-engage with our users and gather their feedback.
Improving clutter:
Instead of showing the timestamp, show the relative time. Move the status pill to the left side for easier scanning. Swap the hierarchy of ID and action in the list.
Instead of showing the timestamp, show the relative time. Move the status pill to the left side for easier scanning. Swap the hierarchy of ID and action in the list.
Implementing a "My Events" Filter:
Add a filter that allowed users to view only their events, to significantly improve navigation and usability.
Add a filter that allowed users to view only their events, to significantly improve navigation and usability.
Enhancing Link Functionality:
Move check logs link outside of the status pill and use a proper <a> tag. Enabling users to open multiple job logs in new windows as per their workflow needs.
Move check logs link outside of the status pill and use a proper <a> tag. Enabling users to open multiple job logs in new windows as per their workflow needs.
Optimizing Performance:
Collaborating with the engineering team, we removed the unnecessary job attempt counts from the UI which fixed performance problems in querying large amounts of data.
Collaborating with the engineering team, we removed the unnecessary job attempt counts from the UI which fixed performance problems in querying large amounts of data.